> One striking characteristic of Grothendieck's mode of thinking is that it seemed to rely so little on examples. This can be seen in the legend of the so-called "Grothendieck prime". In a mathematical conversation, someone suggested to Grothendieck that they should consider a particular prime number. "You mean an actual number?" Grothendieck asked. The other person replied, yes, an actual prime number. Grothendieck suggested, "All right, take 57."
As a curiosity, the contrast between Grothendieck and Ramanujan is very striking. One famous story about Ramanujan from Wikipedia (https://en.wikipedia.org/wiki/1729_(number)):
"Hardy stated that the number 1729 from a taxicab he rode was a "dull" number and "hopefully it is not unfavourable omen", but Ramanujan remarked that "it is a very interesting number; it is the smallest number expressible as the sum of two cubes in two different ways"."
They, of course, were very different personalities, doing very different mathematics with very different impacts on the field. I always found it interesting that Ramanujan seemed to be very comfortable with numbers, their properties, patterns (continued fractions) and Grothendieck was very comfortable with structures and their rhythms without paying attention to concrete examples.
It looks like a prime, but can be caught with the second-simplest test: sum of the digits is 12, which is divisible by 3. Hence it's divisible by 3.
(The simplest test being of course if the number is even and bigger than 2)
Edit: now that I think about it, probably should not have tried to impose ordering to the simplicity of tests. There's of course the divisibility by 5 test, which is even simpler.
In fact, most 2 digit numbers not divisible by 2, 3, or 5 are prime. [1] The only one that's likely to ruin your day is 7 * 13 == 91, but that's self-defeating because after you think about it long enough 91 falls victim to [2].
I just noticed that it's 60-3 without any divisibility tests.
Tao's 27 prime was much more embarassing but understandable as he's no a calculator.
Savants are for things like remembering the first million primes. Someone like Tao or Grothendieck can't remeber them beyond 20, but it doesn't mean they can't actuly reason about them.
I attended a talk by Rasmus Lerdorf at a FOSS conference in 2006. It has been a long time, so I remember only a few things from the talk, but one thing I remember him talking about is how people love to complain about PHP, often on forums that are themselves written in PHP.
Rasmus also admits that he didn't really know what he was doing when he created PHP, and that it's a bit surprising that PHP has stayed as compatible as it has. I kind of respect him more for that than I once used to.
I remember it being somewhat common for people to make forum posts consisting entirely of a joke image. However, they weren’t called memes at the time as the word had yet to be popularized.
But it's always been correct to interrupt a discussion on a PHP forum about PHP security by breaking into Rasmus's account and posting an ironic meme under his name.
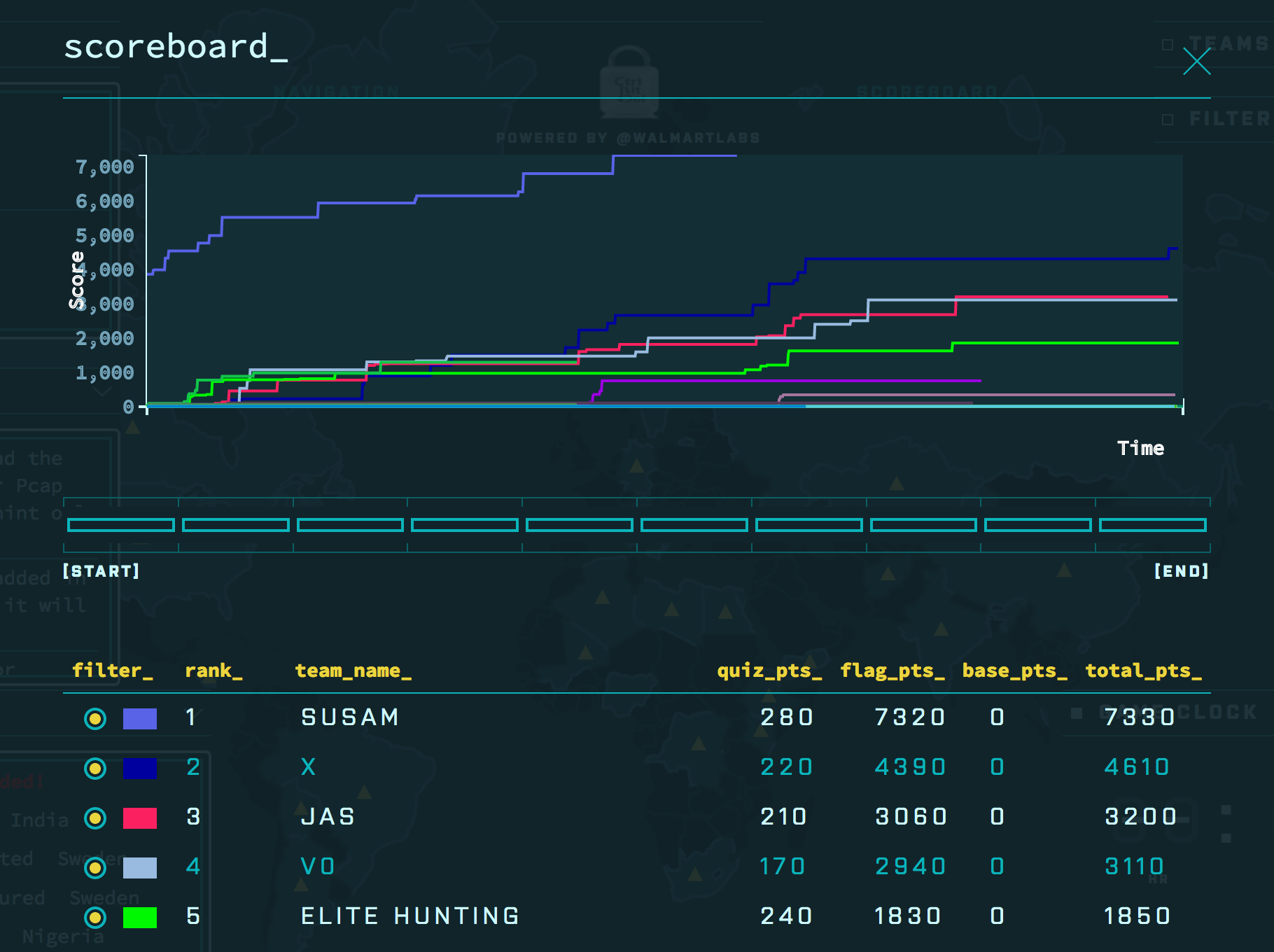
I have normally found any sort of timed technical competition intimidating. Even so, about 6 or 7 years ago, after being persuaded by a colleague, I participated in a few CTFs. I am glad I did, back when this type of thing still meant something. I have kept a screenshot from one of the CTFs that I am quite fond of: https://susam.net/files/blog/ctf-2019.png
This is fantastic! The voting statistics of the community would have been very interesting. I have emailed the moderators to see if they would consider giving this post a second chance at /pool.
I do remember that this particular code snippet (with a = 5, even) used to be popular as an interview question. I found such questions quite annoying because most interviewers who posed them seemed to believe that whatever output they saw with their compiler version was the correct answer. If you tried explaining that the code has undefined behaviour, the reactions generally ranged from mild disagreement to serious confusion. Most of them neither cared about nor understood 'undefined behaviour' or 'sequence points'.
I remember one particular interviewer who, after I explained that this was undefined behaviour and why, listened patiently to me and then explained to me that the correct answer was 17, because the two post-increments leave the variable as 6, so adding 6 twice to the original 5 gives 17.
I am very glad these types of interview questions have become less prevalent these days. They have, right? Right?
IMO, The only reasonable answer if asked this in an interview is “I would not write code where I have to know the answer to this question”
These sorts of things are neat trivia to learn about things like sequence points but 99.9% of the time if it matters in your codebase you're writing something unmaintainable.
> IMO, The only reasonable answer if asked this in an interview is “I would not write code where I have to know the answer to this question”
That's half of a reasonable answer. The other half is "but I do know the answer so if I see it when reviewing or working on someone else's code I can flag it or rewrite it, and explain to them why it is bad".
If you claim to know the answer you've made a grave mistake and fooled yourself.
If you ran the code in a compiler and used that to conclude "this is the answer" rather than "this is an answer" then now is a great time to learn how easy it is to fool yourself. You just need you ask yourself what assumptions you made. I'll wager you assumed all compilers process this line in the same way.
Or just RTFA, or Susam's, as that's exactly what they are about. They explain why this is undefined behavior.
| The first principle is that you must not fool yourself — and you are the easiest person to fool.
- Feynman
> I'll wager you assumed all compilers process this line in the same way
You would lose that wager.
What I mean by "I do know the answer" is that I know that this is undefined behavior and why it is undefined behavior and that different compilers can give different results and also that even if I test the compiler I use to see what it does I can't count on that not changing any time the compiler gets updated.
Fair, but that was not clear to me that that's what you meant. It's clear that others interpreted it the way you intended too (since there are multiple replies saying exactly what you said) but I also don't think I'm the only one who misinterpreted. Sorry that I did.
Syntactically, it is valid. Though yes, semantically it is invalid. Calling it "valid" is going to just continue the same problem because there's multiple ways to interpret valid here
Right, the feedback I'd expect in a code review interview is something like "This is unclear or wrong, write what you actually meant".
That's the feedback I would want, and it's the feedback I give to my colleagues in reviews. Actually I tend to be too verbose, so you might get a full paragraph explaining what the ISO document says and that you shouldn't assume it does whatever it is your compiler says.
My actual feelings for this specific case are that the language is defective, but if we're wedded to a defective language then the reviews need to call out such usage.
> Actually I tend to be too verbose, so you might get a full paragraph explaining what the ISO document
I'm verbose too, but I love it when others are. Honestly, it's usually easy to triage (and I write to try to make it easy). I like verbosity because learning why means I not only won't make that mistake again but I won't make any similar mistakes again.
Verbosity isn't bad. Not everything needs to be a fucking tweet
That isn't a strong answer, unless the question was about what you think of the code's style. The point is that it's more than just poor style, it's likely to constitute undefined behaviour. Saying different compilers could interpret the expression differently is not equivalent to saying it invokes undefined behaviour.
It's common for interview questions to explore unusual code, perhaps poor quality code, that hinges on edge cases of the language. A candidate with a strong understanding of the language would be expected to take the opportunity to demonstrate it.
You might still make a mistake, even if you think you know the answer. It's much better to instrument the code to figure it out, or write a short test program.
It's Undefined Behavior. So you can instrument all you want, the answer will still be wrong. You'll capture what your particular compiler does under some particular conditions (opt flags, surrounding code, etc.) but that will not be representative of what can happen in the general case (hint : anything can happen with UB).
Susam's post doesn't make this clear. The quotes from K&R say that the modifications to the variable may take place in any order, but they don't directly say that doing this is Undefined Behavior, which would make it permissible to do anything, including e.g. interpreting the increments as decrements.
The C99 standard is quoted saying this:
>> Between the previous and next sequence point an object shall have its stored value modified at most once by the evaluation of an expression.
It's possible that something else in the standard defines noncompliance with this clause as Undefined Behavior. But that's not the most intuitive interpretation; what this seems to say, to me, is that the line of code `a = a++ + ++a` should fail to compile, because it's not in compliance with a requirement of the language. Compilers that produce any result at all are suffering from a bug.
(It seems more likely that the actual intent is to specify that, given the line of code `b = a++ + ++a`, with a initially equal to 5, the compiler is required to ensure that the value stored at the address of a is never equal to 6 - that it begins at 5, and at some indefinite point it becomes 7, but that there is no intermediate stage between them. But I find the 'compiler failure on attempt to put multiple modifications between two sequence points' interpretation preferable.)
The "shall" in the standard means it's undefined behavior. This is explained in the "Conformance" section,
> 2. If a ‘‘shall’’ or ‘‘shall not’’requirement that appears outside of a constraint is violated, the behavior is undefined. Undefined behavior is otherwise indicated in this International Standard by the words ‘‘undefined behavior’’ or by the omission of any explicit definition of behavior. There is no difference in emphasis among these three; they all describe ‘‘behavior that is undefined’’.
Compilers will not refuse to compile the code, indeed the blog post we are all commenting on reports the results from a bunch of different compilers. Historically the reason the C standard specified a lot of undefined behavior is that the actually existing C compilers at the time compiled the code but disagreed about the output.
> Compilers will not refuse to compile the code, indeed the blog post we are all commenting on reports the results from a bunch of different compilers.
Because this specific UB is static (not usually the case) both gcc and clang will flag it if Wsequence-point is enabled (and it is part of Wall) (technically the clang warning is Wunsequenced but aliased to the GCC version).
edit: apparently Wunsequenced is enabled by default so clang should warn you out of the box.
Compilers are not able to prevent you from violating must/shall in the general case. So they're not held to that bar. Unless the standard says not to compile it, it's not a compiler bug.
Also, imagine a situation where the line of code actually lists three different variables, but all three of them are passed in by address. It quickly becomes impossible for the compiler to know you violated the spec by reusing the same variable. And even optimizations that make sense here could corrupt the value pretty badly and possibly lead to worse errors.
> Also, imagine a situation where the line of code actually lists three different variables, but all three of them are passed in by address. It quickly becomes impossible for the compiler to know you violated the spec by reusing the same variable.
OK. What is the value of a spec to which compliance is impossible?
The compiler does comply to the spec. It's the program that fails to comply with the spec. It's definitely possible to write programs that have no undefined behavior.
The compiler is supposed to compile programs that comply with the spec, and not compile programs that don't.
The concept of "compiling a program that doesn't comply with the spec" doesn't even exist! A text file that doesn't comply with the C spec isn't a C program. That's what it means to be "the spec".
No, there's a fun C++ talk - by I want to say Chandler Carruth - in which the speaker points out that C++ is a language defined to have false positives for the question "Is this a valid program?"
The mechanism in the ISO document is phrases of the form "Ill-formed, No Diagnostic Required" which is often shortened to IFNDR. Lets break that down. "Ill-formed" means this is not a valid C++ program. On its own that means the compiler should provide a diagnostic (an error messag) explaining that your program isn't valid. For example if the program text were to just consist of the word "fuck" that's ill-formed and will be diagnosed. "No Diagnostic Required" says in this case though, we don't require the compiler to report this problem.
Why do that? So originally there's a purely practical reason, but ultimately there's a philosophical one. C++ like C before it wants to translate many individual program files and then somehow cobble the resulting output into a single executable. So this means function A over here, using type T from a different file cannot know for sure about type T, instead C++ has a thing called the "One Definition Rule" which says you must somewhat define T each time it's needed, but all the definitions must be the same. What if you don't (by mistake or on purpose)? Well that will cause chaos, so, IFNDR.
Philosophically IFNDR is a way to resolve the dilemma from Rice's Theorem. Back in about 1950 this guy named Henry Rice got his PhD for proving that any non-trivial semantic property of a program is Undecidable. This isn't "Oh no, it's quite hard to do this" it's a straight up mathematical proof that it can't be done. Deciding reliably whether a program has any† semantic property isn't possible. Sometimes we're sure, and that's fine, but the dilemma is for the tricky cases: What do we do when we're not sure?
IFNDR is C++ choosing "Fuck it, it's fine" for this case. Maybe your program is nonsense, it might do absolutely anything, but you don't get even a warning from the compiler. This is Chandler's "false positive".
Rust chooses the opposite. When the compiler can't see why your program is sense it will be rejected, even if you and a room full of compiler experts agree it should work too bad, it doesn't compile. You get a diagnostic explaining why your program was rejected.
† Trivial means either all programs have the property or none do and so isn't interesting. As a result the restriction to "non-trivial" properties isn't much help.
> The concept of "compiling a program that doesn't comply with the spec" doesn't even exist!
Wrong. Lots of spec violations only happen at runtime and can't be predicted at compile time.
Here's an easy example. You're the compiler. I hand you what appears to be valid C code that allocates an array and then asks the user which slot to use. It doesn't verify the slot is in bounds, just puts a number in array[slot], does some math with it, and then prints the result. Does my program comply with the spec? Do you compile it?
This is "Wrong" in the sense that C++ does really work like this, but it's not wrong in the sense that this is somehow unavoidably the case.
For example if you attempt an equivalent mistake in WUFFS that will be rejected.
Your WUFFS compiler will say this variable named slot must be a non-negative integer smaller than the length of the array, but as far as it can tell you didn't ensure that was true, therefore this code is nonsense, do better.
As I explained in my sister reply, in a broader context some of these are semantic properties and so there's a dilemma and C++ chooses to resolve that dilemma by accepting nonsense programs, but that wasn't the only available resolution and I am confident it's the wrong choice.
That may be how you want C to be specified, but that's not how C is specified. The compiler is always allowed to assume that the input program is free of undefined behaviors.
C++ has an even more trivial example: To be a valid C++ program, all loops without side-effects must terminate. Thus determining if some C++ programs are valid would require solving the halting problem.
Assembly is kind of at the crossroads of everything being defined and nothing being defined, when you consider things like writing random data to memory and executing it... But anyway here's the first thing I found to answer that: https://news.ycombinator.com/item?id=9578178
Probably more important, way too many things in assembly vary by exact model. Can you name a portable language that fits those criteria?
>What is the value of a spec to which compliance is impossible?
Are you saying, what's the value of a language spec that allows undefined behavior, as C does?
Well, it's that it allows for compiler implementations that aren't too hard to implement and maintain.
It allows for a language that's close enough to hardware (and allows you to do programming on a low level), while still offering a reasonable amount of abstraction to be useful (and usable).
It's also difficult to define a formal system that won't have undefined expressions. Mathematics itself is full of them (in logic, "this sentence is a lie" has no truth value; you can't define the set of all sets, or a set of sets that don't contain themselves; etc).
That said, I think we've settled on a rather silly choice here with the "++" operator.
Personally, I'd do away with the ++ operator in either pre- or post- increment forms, or at least disallow it in arithmetic expressions.
The only thing having it realistically accomplished is saving a few characters when writing a for-loop in C.
Even for that it's not necessary.
The problem with it is that, unlike normal arithmetic operators, it both returns a value and assigns one, which means that you can assign values to several variables in a single arithmetic expression, as in
a = b++;
...which C, in general, allows, as in:
a = (b = b + 1);
The result of these two expressions, of course, is different.
Now, I have the following religious belief, and it's that arithmetic operators shouldn't have side effects. That's to say, assignment and evaluation should be separate.
So that when I write
x = (arithmetic);
..I could be sure that the only outcome of this computation is changing the value of x.
Perhaps calling the function sqrt(x) would summon Cthulhu — I'll read the documentation for it to be sure. But in general, I'd hope that calling abs(x) wouldn't change the value of x to |x| in addition to returning it.
But K&R decided to have fun by saying that "x = 5;" is both an assignment and an expression with a value. Which allows one to write:
x = y = z = 5;
as a parlor trick.
That's it, that's the only utility.
Instead of defining this as a special initialization syntax and otherwise disallowing it (as Pyhthon does), they went YOLO and made assignment an expression rather than a mere statement.
Which means that the very useful statement "increase the value of this variable by one" became two expressions with different values.
In an ideal world, the following would be equivalent, and would not evaluate to anything you can assign to a variable:
++x;
x += 1;
x = x + 1;
...while "x++" would not exist at all (or would be equivalent to ++x).
And that's how it is in Go. Thompson fixed the design mistake after 4-5 decades of it giving everyone headaches.
Sadly, C++, Java, C# all wanted to be "like C" in basic syntax, so we're stuck with puzzles like this to this day.
TL;DR: if you're asking "what's the value of the spec that makes assignment an expression", i.e. why is making "a = (b = c + d);" valid syntax a good idea, the answer is:
It isn't. It's a bad decision made in 1970s that modern languages like Go no longer support.
> Well, it's that it allows for compiler implementations that aren't too hard to implement and maintain.
> It allows for a language that's close enough to hardware (and allows you to do programming on a low level), while still offering a reasonable amount of abstraction to be useful (and usable).
I can see the first of these. The second appears to be untrue; if you removed the concept of undefined behavior from C, it wouldn't get farther away from the hardware.
Is that first point actually something that somebody wants? Who benefits from the idea that it's easy to write a "standards-compliant" compiler, because you are technically "standards-compliant" whether you comply with the standard or not?
At that point, you've given up on having a standard, and the interviewers Susam calls out, who say that the correct answer is whatever their compiler says it is, are correct in fact. Susam is the one who's wrong, for reading the standard.
You can run a language that way just fine. I had the impression that Perl was defined by a reference implementation. But it's the opposite of having a standard.
>The second appears to be untrue; if you removed the concept of undefined behavior from C, it wouldn't get farther away from the hardware
My understanding is that even common CPU instruction sets can have undefined behavior[1].
When C was written, the CPU architectures were more of a Wild West. It might have made sense to leave some parts up to the compiler authors on a particular architecture.
>Is that first point actually something that somebody wants?
When C was written — absolutely.
Portability of C code is almost taken for granted these days.
Things were different then. Portability was a big challenge.
All that said, this is my non-authoritative understanding of the reasons why it's a thing. Take it with a grain of salt.
>At that point, you've given up on having a standard
Sure. Just treat C as a family of languages which have a common standardized part.
Proprietary compiler extensions are/were common anyway, so that's not an unusual situation.
Assigning to multiple variables in a single expression is fine and useful. Take
```
target[i++] = source1[j++] + source2[k++];
```
That's idiomatic, it shows the intent to read and consume the value in a single expression.
You can write it longer, but not more clearly.
It's only when you assign to the same variable multiple times, or read it after it was assigned, that it introduces ordering issues.
A single `i++` or `++i`/`i += 1` is safe and useful.
If you only have a single index, that you continue to increment, you don't need an index at all, you just invoke memcpy.
It is useful to distinguish between consuming an element and only jumping to it. So you would have an ptr[i++] for consuming the current token, but not, when you are switching to another token.
A grouping of index and array modification also provides clarity about the intention. It would read very annoying if that constantly would be split into two steps, and also provides more room for error.
It's obvious that you do prefer the stylistic choices Go made, but that doesn't mean everyone does.
>It is useful to distinguish between consuming an element and only jumping to it. So you would have an ptr[i++] for consuming the current token, but not, when you are switching to another token.
So, it's trivial to do it with a function. Or a macro.
int adv(int *i){
int t = *i;
(*i) = t + 1;
return t;
}
while(i < 10)
printf("%d\n", adv(&i));
Not to mention, iterators and all that jazz.
The point is, you don't need assignment to return a value to have this.
Can you give a non-contrived example where you really need it?
>It's obvious that you do prefer the stylistic choices Go made, but that doesn't mean everyone does.
It's not that I "prefer stylistic choices of Go", it's that I hate to have undefined behavior in language spec which is easy to stumble into - the cost of the "stylistic choice" that C made doesn't make that choice justified.
I searched K&R to see if there is any language that implies a += a++ + a++ to be undefined. I couldn't find anything. I found the following excerpt which is closest to what I claim, in spirit. But still, it does not explicitly spell out that an object must not be modified more than once between sequence points. From § A.7 Expressions:
> The precedence and associativity of operators is fully specified, but the order of evaluation of expressions is, with certain exceptions, undefined, even if the subexpressions involve side effects. That is, unless the definition of the operator guarantees that its operands are evaluated in a particular order, the implementation is free to evaluate operands in any order, or even to interleave their evaluation. However, each operator combines the values produced by its operands in a way compatible with the parsing of the expression in which it appears. This rule revokes the previous freedom to reorder expressions with operators that are mathematically commutative and associative, but can fail to be computationally associative. The change affects only floating-point computations near the limits of their accuracy, and situations where overflow is possible.
So I think, the text in K&R serves as warning against writing such code, at best. The C99 draft has more relevant language. From § 4. Conformance:
> If a "shall" or "shall not" requirement that appears outside of a constraint is violated, the behavior is undefined. Undefined behavior is otherwise indicated in this International Standard by the words "undefined behavior" or by the omission of any explicit definition of behavior. There is no difference in emphasis among these three; they all describe "behavior that is undefined".
This along with the § 6.5 excerpt already mentioned in my post implies a += a++ + a++ to be undefined. When I get some more time later, I'll make an update to my post to include the § 4. Conformance language too for completeness.
No, the behavior is undefined. That means, quoting the ISO C standard, "behavior, upon use of a nonportable or erroneous program construct or of erroneous data, for which this document imposes no requirements".
A conforming implementation could reject it at compile time, or generate code that traps, or generate code that set a to 137, or, in principle, generate code that reformats your hard drive. Some of these behaviors are unlikely, but none are forbidden by the language standard.
I'm not sure where precisely this sequencing exception to the default "eval order undefined" rule is given, but after the 24(!) sequencing rules they do give this "++i + i++" as an explicit example of undefined behavior.
Interestingly that page says that since C++17 f(++i, ++i) is "unspecified" rather than "undefined", whatever that means, and presumably plus(++i, i++) would be too, which seems a bit inconsistent.
But since it is a UB, there's no guarantee that your test program produces the same result as the same code running on production, even if you have the same compiler.
On one hand I've been using almost the exact statement 25 years ago in my Flash (ecmascript) tutorials to narrow down the point of operator precedence.
I still believe it's a good piece on your powerpoint if you want to teach.
It's easy to fall, easy to grasp, and easy to unroll all the rules - that is, if the rules are actually set in stone.
On the other hand I've been through couple FAANG interviews, and twice I was presented with something similar and after I glanced at it for a half a minute the interviewer quickly proceed to "a ha!, you don't know! the interview is over , but I'm happy to tell you the right answer".
The answers to some questions must be known in order to be able to write a correct program.
In the vast majority of the programming languages, the order of evaluation for the actual parameters passed to a function is undefined. In the few programming languages where the order of evaluation is defined, that is actually a mistake in the design of that programming language.
This is something about which any programmer must be well aware, because when composing function invocations it is very easy to write a function invocation where the result would depend on the order of evaluation of the expressions passed as actual parameters. The arithmetic operators are also function invocations, so that applies to them too.
> when composing function invocations it is very easy to write a function invocation where the result would depend on the order of evaluation of the expressions passed as actual parameters
this simply means your functions aren't pure functions, and is doing side effects. If you rewrite those functions to not have side effects (including ones being used to generate the parameters), there would be zero issues of such nature.
In some sense, and without the interviewer knowing, that is actually a great scenario for an interview.
If you can convince someone in a position of authority that they’re wrong about something technical without upsetting them then you’re probably a good culture fit and someone who can raise the average effectiveness of your team.
I know I did recommend someone after the interview because I looked it up and they were right. Great person to work with. Though I fully understand why most would hesitate.
The best interview questions spawn discussions. This is a pretty good one for that. We could dive into what makes it UB, why a particular compiler might do it a certain way, what results we'd likely see from other compilers, and why the standard might say that this sort of thing is UB.
"What does this produce?" and expecting an answer of "17" is a bad question even if UB didn't mean the expected answer is wrong.
I don’t work a ton with C, but I wonder how C programmers keep track of what behavior is and is not defined. It seems like there are many possible edge cases.
We get by on a combination of matching patterns (any pointer cast gets a lot of scrutiny, for example), compiler warnings, tools like UBSan, debugging when things go wrong, and sheer dumb luck.
Having an understanding of how the code gets transformed into machine code helps. For this case, there's the basic idea that `a++` will boil down to three basic conceptual operations: fetch, add, and store, and those can be potentially interleaved with other parts of the statement. In something like `a++ + ++b` the interleaving doesn't affect the outcome no matter how it's done. In `a++ + ++b` the interleaving can affect the outcome, and that's your sign that something might be wrong.
Any memory safety issue in C code had to involve UB at some point. And you can see how prevalent those are, and deduce how not-particularly-great we are at keeping track of UB.
> Having an understanding of how the code gets transformed into machine code helps
I'm not sure about that. Knowing assembly is not a substitute for knowing how the language is defined. Sometimes C/C++ programmers with some assembly knowledge reason themselves into thinking that what they're asking of the language must have well-defined behaviour, when in fact it's undefined behaviour. It doesn't really matter whether interleaving order can change the output. (++i)++ is, apparently [0], undefined behaviour in C but has well defined behaviour in C++.
I don't mean assembly in this case, but something more like the compiler's view of the code. a++ can be broken down into more primitive operations, and might actually be, depending on how the compiler is implemented. The fact that the ordering of those more primitive operations with respect to other operations isn't very tightly constrained is something you'd just have to know about the language, I suppose.
> The fact that the ordering of those more primitive operations with respect to other operations isn't very tightly constrained is something you'd just have to know about the language, I suppose.
No, that's not right. It's undefined behaviour, not merely an unspecified order of evaluation. Roughly speaking, the behaviour of the entire program is unconstrained by the language standard after execution of that statement. It could crash the whole process, for instance, or go haywire.
It's worse than that, the behavior of the entire program is unconstrained by the language standard beforehand too. Raymond Chen discusses how things can go wrong once you're going to reach UB even before you get to it: https://devblogs.microsoft.com/oldnewthing/20140627-00/?p=63...
Anyway, I didn't mean to imply that things behaved as written aside from ordering issues. I only meant that this sort of principle can help you remember where UB lurks. Generally, where a kind C compiler might just mess with your numbers a bit, an evil C compiler can legally make demons fly out of your nose.
> It's worse than that, the behavior of the entire program is unconstrained by the language standard beforehand too. Raymond Chen discusses how things can go wrong once you're going to reach UB even before you get to it
Heh, yes that's exactly what I was thinking when I put roughly speaking.
> where a kind C compiler might just mess with your numbers a bit, an evil C compiler can legally make demons fly out of your nose
Yes, signed integer overflow being another. Presumably it's defined that way as it's simpler than trying to spell out all the behaviours the compiler is permitted to implement, and on top of that there are trap representations to worry about. I doubt modern compilers get much optimization benefit from it though. There's a StackOverflow thread discussing the reasons it's defined this way: https://stackoverflow.com/q/1860461
Apparently signed integer overflow UB helps with loop optimizations because it makes it easy to prove the loop always terminates. I assume that's not why it's UB, though; surely it's UB because some systems trapped on overflow, or produced different results due to using 1's complement, and the optimization side of the rule was a happy accident. There's a lot of history in this language and it really shows.
> Apparently signed integer overflow UB helps with loop optimizations because it makes it easy to prove the loop always terminates
I tried googling but couldn't find hard numbers on the performance impact of GCC's -fwrapv flag. As you'd imagine, it forces wrapping for overflowing arithmetic on signed integer types. [0]
I also have to wonder how instructive that would be anyway. The GCC devs presumably don't prioritise the performance impact of that flag. If the C language mandated it, they might find other ways to achieve similar optimisation.
This page [1] looks at the related flag for trap-on-signed-overflow, and found an impact of very roughly 6%.
See also: John Regehr's posts on this topic. [2][3] He dislikes Java's implicit wrap behaviour, as it's rarely what the programmer wants to happen. Java programmers almost never use the addExact method, [4] as it's so syntactically clumsy.
> surely it's UB because some systems trapped on overflow, or produced different results due to using 1's complement, and the optimization side of the rule was a happy accident
Per this StackOverflow answer [5] I think you have it right.
They don't. In the culture some kinds of undefined behaviour are taken seriously and some aren't. If you want to write code that "works", you emulate what popular performance benchmarks do (whether their code is undefined according to the standard or not), since those are the thing that C compiler developers actually care about.
Personally, when ever I write a modifying statement, I wonder about the domains of the input and ensure, that the condition necessary to stay in the existing range is evaluated. If it is not, I either write the condition, reduce the input domain, or increase the output domain.
They don't really. In fact there are many things that are technically UB but are so common that compilers can't really treat them as UB. E.g. type punning via unions.
Type punning via unions is not UB in C in general, but it is in C++ IIRC.
I write "in general" because, as with other forms of memory reinterpretation (memcpy or copy through a character type), evaluating a trap representation triggers UB.
And a slightly longer version is, that there are three types involved: the type of access, the effective type of the object[0], and the type of the variable. The type of the variable is only for the compiler to emit warnings, as long as the effective type and the type of access are equal, it isn't UB.
> I am very glad these types of interview questions have become less prevalent these days. They have, right? Right?
Are you referring to the type of interview questions where the question is ill-defined and no one should know the answer, or the type where the question is reasonable and well-defined, but the interviewer doesn't know the answer?
I had a phone screen with Google once where they asked how to determine the length of a stretch of contiguous 1s within an infinite array of 0s. I suggested that, given the starting index i, you can check the index i+2 and then repeatedly square it until you find yourself among the zeroes, after which you can do binary search to find the transition from ones to zeroes.
The interviewer objected that this will grow the candidate end index too quickly, and the correct thing to do is to check index i+1 and then successively double it until you find the zeroes. We moved on.
I passed that phone screen. But I still resent it, because I checked the math later and "successive squaring followed by binary search" and "successive doubling followed by binary search" take exactly the same amount of time.
I meant the latter. I think the question is fine. It can lead to a good discussion, similar to what we are having in this thread. It has been a long time (almost 20 years), but I remember that most interviewers who asked this seemed to be convinced that the output they had seen with their compiler version was the correct answer. What could be a nice and relevant discussion, especially considering that some classes of bugs and security issues result from it, was seen only as a trivia quiz by the interviewers, with the expectation of an answer that was incorrect, no less.
Your phone screen story is quite nice. When I read your question, I would have answered with successive doubling as well. In fact, I faced the same question at an AWS interview a long time ago. The question was mathematically the same question but formulated differently. I answered with the doubling solution too, which leads to an O(log n) time solution, asymptotically. Your interviewer's immediate objection to your squaring solution seems like a major failure in their intuition. When I read your solution, purely by intuition, that is, without resorting to any rigorous reasoning, I felt: wow, that's interesting, your solution would land on the zero region in merely O(log log n) time. Why didn't I think of it? I think your solution should spark interest rather than dismissal in a curious person. Of course, the binary search after that to find the exact transition point blows up the time consumed back to O(log n).
Once again, thanks for these really interesting comments!
From first principles, it seems unlikely that interviewers selecting their own questions would be able to eliminate this class of question, since by definition they cannot know whether the answer they believe is correct really is correct or not.
I would be 100% behind a movement to replace interviewer freedom with externally-set, vetted questions.
Heh, one time when I got this style of question[1] (but for JavaScript), I took a glance at it and said "Um ... you really shouldn't write code like that." The interviewer replied, "Oh. Yeah. Fair point." And then went on to another question.
[1] By which I mean predicting the behavior of error-prone code that requires good knowledge of all the quirks of the language to correctly answer.
Genuinely curious, so this is undefined behavior and depends on the compiler. I get that. Java, and other languages, can do these same operations but their compilers produce bytecode that runs on a virtual machine (JVM) compiled to machine code just-in-time. Would this same code in Java possibly yield different results based on the platform the JVM was running on because of the platform specific JIT compiler? Maybe that's part of the origin of the phrase "write once, test everywhere".
The UB comes from how C++ standard defines expression sequencing which is not relevant for Java. Languages other than C++ typically define such details more strictly so there is no UB or even concept of UB. JIT compilers don't change it as any non toy JIT will generate native instructions directly or through intermediate representation (instead of generating C++ text and passing that through regular C++ compiler) both of which should have much stricter semantics compared to what C++ guarantees.
late to this but what i meant was the JIT Compiler had to be compiled by a compiler at some point so its behavior is defined by the compiler used to compile it (this goes all the way down to the poor soul who hand compiled the first compiler). I'm assuming things like JIT are platform dependent and therefore the compiler used to build it would also be platform dependent. So the JIT on different platforms could have been built from different compilers choosing their own way of handling undefined behavior. ...unless i'm confusing myself which is likely.
> Would this same code in Java possibly yield different results based on the platform the JVM was running on because of the platform specific JIT compiler?
No, and it's also well defined in languages like C#.
If we're talking about this specific example at least. No sequence point issues like that in Java.
It's been quite a while, but IIRC, in Java these statements actually do have a defined behavior.
The ++x is a "pre-increment", meaning the value of the variable is incremented prior to evaluating the expression, while the "post-increment" "x++" is the other way around: the expression evaluates to x, then x is incremented afterwards.
That behavior is inherited from C. The pre/post increment behavior is actually the same in every language that uses them. The priority of operation is also usually the same as well.
The reason the question is tricky is because those operators change the value of a as the full expression is progressively executed.
It's not immediately clear to me what the answer in Java would be.
Just take a++ + ++a for example:
If the value if `a` is hoisted by the jvm then it could be 5++ + ++5, so 5 + 6.
But if it's executed left to right and `a` is looked up every time, then it becomes 5++ + ++6, so 5 + 7.
The value of the variable is not hoisted by the Java compiler. (It's not that JVM, that only executes the byte code, what y doesn't have that kind of ambiguities.)
The semantics of Java is not undefined on multiple assignments to the same variable in an expression, so it can't hoist something if it would change the outcome.
Now, I don't actually know what the outcome is, because I don't remember whether `a += e` reads the value of `a` before or after evaluating `e`. The code is still confusing and unreadable to humans, so you shouldn't write it, but the compiler behavior is not undefined.
And if your variable is accessed from multiple threads, it may be undefined which intermediate values night be seen.
$ cat a.java
class a {
public static void main (String[] args) {
int a = 4;
int b = a++ + ++a;
System.out.println(b);
System.out.println(a);
}
}
$ javac a.java
$ java a
10
6
> I found such questions quite annoying because most interviewers who posed them seemed to believe that whatever output they saw with their compiler version was the correct answer.
Other than the job for most programmers having nothing to do with whether they know the outcome, because hopefully they'd never write something like it or clean it up. And IF they found it they'd hopefully test it - given that it appears to be compiler dependent anyways.
Both major compilers yell at you for this nowadays... it's pretty unforgivable IMHO for somebody to be asking it as an exam or interview question if the right answer isn't "undefined":
<source>:5:10: warning: multiple unsequenced modifications to 'a' [-Wunsequenced]
5 | a = a++ + ++a;
|
<source>:5:7: warning: operation on 'a' may be undefined [-Wsequence-point]
5 | a = a++ + ++a;
| ~~^~~~~~~~~~~
Maybe the interviewer seeks to hear something like "This is UD, this code needs to be rewritten, should not pass code review. What prevents you from using -Wall when compiling?"
Well... tried it on macOS using vanilla gcc, the results surprised me:
$ /bin/cat x.c; gcc -w -o x x.c; ./x
#include <stdio.h>
int main()
{
int a = 5;
a += a++ + a++;
printf("a = %d\n", a);
}
a = 18
Not what I expected.
This must be how it works:
- The first a++ expression results in 5, after a = 6
- The second a++ expression results in 6, after a = 7
- Only then the LHS a is evaluated for the addition-assignment, so we get:
a = 7 + 5 + 6 = 18
I remember dBASE IV from my childhood days when my father, who had no computer background, was required to take computer training by his workplace. My father and his colleagues were given free evening computer lessons by their company, taught by the same teachers who used to teach us, the kids, computers in our school.
After their first class, he brought home a fat dBASE IV manual. Since I was very interested in computer books, I read a good portion of it even though I had never touched dBASE in my life. I would daydream of all the little forms, queries, reports and labels I could make with dBASE. But I never got to touch dBASE in my life. We kids used to get LOGO lessons instead in school.
One day my father came back from his evening lesson mildly distressed about something he had learnt. He said they were being taught loops but in the loop there was an equation that seemed just plain wrong. It was:
i = i + 1
How could that be a valid equation? How could i ever equal i + 1? He mentioned that he had asked the teacher about it and from what I could gather, my teacher and my father were talking past each other. The teacher probably tried explaining that it was not an equation but an instruction instead, whereas my father continued to interpret i = i + 1 as an equation due to the algebra he was so familiar with. It sort of held up the class for a while.
The teacher asked my father's name, perhaps so that he could talk to him separately later. But when he learnt my father's name, he realised that his son, me, went to the same school where he taught. So he told my father, 'When you get back home, ask your son about i = i + 1. He will explain it to you better than I am able to.'
And indeed I was able to explain it to him pretty well. I was eight or nine years old back then. And that was probably the first thing I taught my father!
The = for assignment is FORTRAN’s fault. In the beginning there was no equality, just assignment, and FORTRAN (being just a FORmula TRANslator after all) made the somewhat dubious decision to use = for that (punch card space being sparse and symbols limited and all).
When FORTRAN gained equality it went for .EQ. out of practicality and necessity. Many others followed suit but used the somewhat more pleasant == instead of .EQ..
But it didn’t have to happen that way. ALGOL decided to stick close to mathematical tradition:
= for equality
:= for assignment ("definition")
While x := x + 1 is still not clean mathematical notation, I think it wouldn’t have riled up OP’s father as much. If he’d squinted enough, he might even have been able to see little indices below the x’s there.
Splitting = and := is intentional, but not for the reason you stated. We could have used := for all assignments from the beginning:
is_logged_in := True
or
if is_logged_in := True:
I agree that this would require blurring the statement/expression distinction. You can still do that in a weird way, by disguising your assignment as an expression. This is valid:
(is_logged_in := True)
The reason it was done that way because := was an afterthought, and making it the assignment operator would have introduced a breaking incompatibility. That lead to having 3 different symbols for 2 use cases (assignment and comparison).
In some of the draft versions of ASCII the positions currently taken by underscore and caret were left arrow and up arrow respectively. As late as 1985 I used terminals (LanparScope) the supported the older draft.
All Commodore machines also uses the older ASCII standards, (in addition to filling out the full 8 bit range with various graphics). It’s usually referred to as “PETSCII”, from the original Commodore “PET” series, but PETSCII was also used in the vastly more popular Commodore 64 (and 128) home computers.
But why? := is perfectly understandable and established notation for definition. You don't get closer assignment without resorting to esoteric notation?
Grammatically, this would not change X. "...GIVING X" would just return X. Since it's part of the same statement, it seems it should ignore the "ADD 5 TO X" part.
Now, if you'd like to place the result into X, I suggest "ADD 5 TO X" would suffice as the entire statement.
Think that was just to make the parser understand it was an assignment without having to do any lookahead. There was also possibly ambiguous stuff with equality and assingment as they both used =.
As kids we had the same debate because we were taught algebra before BASIC, and naturally tried to interpret it mathematically. Fortunately, sometimes a kid can explain it better to other kids than an adult, and that was the case.
Some of my earliest programming exposure was a dBASE IV book my dad had for work, though it was some time before I put any of it into action. At that time I was reading manuals like fiction, only slowly realizing that I could actually use some of it with our computer.
It's a notational issue. IIRC Pascal used := for assignment and = for equality testing.
Where this becomes extremely Rorsarch is the spectrum between "notation is absolutely critical: there is only one correct representation of programs in people's heads and we have to match that exactly" vs. "all program text is ultimately syntactic sugar and programmers will just adapt to whatever". History tells us that the C choice of = for assignment and == for equality testing won, but of course that's not a choice in a vacuum and it's tied up with a thousand other choices.
If you have no concept of destructive manipulation of variables, because all the variables you have ever known were the ones in math, you will still read := as equals.
Yes! In lazy but immutable languages like Haskell, it is totally fine to refer to the value itself during definition. This is really the same idea that a recursive function can refer to itself during definition. It’s common to define a variable for the infinite list of prime numbers, where the definition requires the list of prime numbers itself.
primes = 2 : sieve primes [3..]
sieve (p:ps) xs = let (h, t) = span (< p*p) xs in h ++ sieve ps (filter (\n -> rem n p > 0) t)
Here `primes` is a variable that refers to itself in its definition (called corecursion), and `sieve` is a recursive function.
While I'm a big fan of immutable design, it makes some algorithms much more expensive and ultimately DRAM is mutable. And the example we're talking about could be a loop counter!
A tail-recursive loop handles loops just fine, and is just as efficient. This is a perfect example of the misconceptions that mutable-first programming languages have caused.
> ultimately DRAM is mutable
Ultimately the CPU executes machine code, but I don’t see you directly writing that. You’re cherry-picking to defend an indefensible position.
This tells a lot of about your dad - he must be an amazing person, so he was ready to learn something from his kid. Not everyone would be able to admit that 9 y.o. can teach him something :)
Thank you for highlighting that answer. It is one of my favourite pieces of writing about the culture of mathematics. I just want to add that that particular answer is now affectionately known as Thurston's Paean.
Good pedagogy is a problem even for graduate-level mathematics students and professional mathematicians. The proofs in many graduate-level mathematics textbooks are, in my humble opinion, not really proofs at all. They are closer to high-level outlines of proofs. The authors simply do not show their work. The student then has to put in an extraordinary amount of effort to understand and justify each line. Sometimes a 10-line argument in a textbook might expand into a 10-page proof if the student really wants to convince themselves that the argument works.
I am not a mathematician, but out of personal interest, I have worked with professional mathematicians in the past to help refine notes that explain certain intermediate steps in textbooks (for example, Galois Theory, by Stewart, in a specific case). I was surprised to find that it was not just me who found the intermediate steps of certain proofs obscure. Even professional mathematicians who had studied the subject for much of their lives found them obscure. It took us two days of working together to untangle a complicated argument and present it in a way that satisfied three properties: (1) correctness, (2) completeness, and (3) accessibility to a reasonably motivated student.
And I don't mean that the books merely omit basic results from elementary topics like group theory or field theory, which students typically learn in their undergraduate courses. Even if we take all the elementary results from undergraduate courses for granted, the proofs presented in graduate-level textbooks are often nowhere near a complete explanation of why the arguments work. They are high-level outlines at best. I find this hugely problematic, especially because students often learn a topic under difficult deadlines. If the exposition does not include sufficient detail, some students might never learn exactly why the proof works, because not everyone has the time to work out a 10-page proof for every 10 lines in the book.
Many good universities provide accompanying notes that expand the difficult arguments by giving rigorous proofs and adding commentary to aid intuition. I think that is a great practice. I have studied several graduate-level textbooks in the last few years and while these textbooks are a boon to the world, because textbooks that expose the subject are better than no textbooks at all, I am also disappointed by how inaccessible such material often is. If I had unlimited time, I would write accompaniments to those textbooks that provide a detailed exposition of all the arguments. But of course, I don't have unlimited time. Even so, I am thinking of at least making a start by writing accompaniment notes for some topics whose exposition quality I feel strongly about, such as s-arc transitivity of graphs, field extensions and so on.
These days it's easy to just look for the details to any proof on mathlib. Of course a computer checked proof is not always super intuitive for a human, but most of the time it does work quite well.
{kind=link}
> One striking characteristic of Grothendieck's mode of thinking is that it seemed to rely so little on examples. This can be seen in the legend of the so-called "Grothendieck prime". In a mathematical conversation, someone suggested to Grothendieck that they should consider a particular prime number. "You mean an actual number?" Grothendieck asked. The other person replied, yes, an actual prime number. Grothendieck suggested, "All right, take 57."